페이지는 사용자가 빠른 메모부터 공유문서, 랜딩페이지에 이르기까지 모든 것을 작성하는 곳입니다. 통합을 사용해 사용자는 콘텐츠를 조직하여 Notion을 단일 소스로 변경하거나 Notion내에서 콘텐츠를 수집, 연결, 시각화할 수 있습니다.
이 가이드에서는 페이지 콘텐츠의 구성요소가 API에 표시되는 방식과 이를 사용하여 수행할 수 있는 작업에 대해 알아보도록 하겠습니다. 이 가이드를 통해 사용자는 콘텐츠가 포함된 새 페이지를 만들고 다른 페이지의 콘텐츠를 읽어와 기존 페이지 블록에 추가할 수 있습니다.
1. 페이지 콘텐츠와 속성.
일반적으로 페이지 속성은 기한, 범주, 다른 페이지와의 관계 같은 구조화된 정보를 저장하는데 적합합니다. 페이지 콘텐츠는 좀 더 느슨한 구조나 자유 형식 콘텐츠를 저장하는데 적합합니다. 페이지 콘텐츠는 사용자의 생각을 작성하거나 이야기하는 곳입니다. 페이지 속성은 사용자가 데이터를 저장하고 시스템을 구축하는 곳입니다. 여러분의 통합은 여러분이 기대하는 대로 속성과 콘텐츠를 사용하는 것을 목표로 해야 합니다.
모든 단락 블록에는 object, type, created_time, last_edited_time, has_children의 공통된 속성을 포함합니다. 또한 단락 속성 내에 type-specific 정보가 포함되어 있습니다. 단락 블록에는 "text" 속성이 존재하며 블록 타입에 따라 type-specific 속성이 달라질 수 있습니다.
이제 블록에 자식 블록이 있는 예시를 살펴보도록 하겠습니다. "paragraph"에 들여 쓰기 된 "to_do" 블록을 확인해 보세요.
서식이 있는 텍스트 객체는 type-specific 한 구성과 유사한 패턴을 따릅니다. 위의 서식이 있는 텍스트 객체에는 "text" 타입이 있으며 "text" 속성에 해당 타입과 관련된 추가 구성이 존재합니다. annotations, plain_text, href와 같은 타입에 의존하지 않는 기타 정보들은 서식이 있는 텍스트 객체의 최상위 수준에 위치하게 됩니다.
서식이 있는 텍스트는 페이지 콘텐츠와 내부 페이지 속성 값 모두에 사용될 수 있습니다.
4. 콘텐츠가 있는 페이지 만들기.
페이지 생성 엔드포인트를 사용하면 자식 블록을 통해 페이지를 만들 수 있습니다. 이 엔드포인트는 다름 페이지 내에서 페이지를 만들거나 데이터베이스 내에서 페이지 만들기를 지원합니다.
샘플 콘텐츠가 있는 다른 페이지 내에 페이지를 새로 만들어 보도록 하겠습니다. 이 엔트포인트에 대해 세 가지 파라미터를 사용하게 됩니다. "parnet" 파라미터는 부포 페이지가 됩니다. 기존의 페이지 ID를 사용할 수 있습니다.
"properites" 파라미터는 페이지 속성을 표현하는 객체입니다. 우선 이 예시에서는 "title" 속성만이 있는 간단한 페이지 속성을 구성하도록 하겠습니다.
{
"Name": {
"type": "title",
"title": [{ "type": "text", "text": { "content": "A note from your pals at Notion" } }]
}
}
"children" 파라미터는 페이지 콘텐츠를 표현하는 블록 객체 목록입니다. 몇 가지 샘플 콘텐츠를 사용하도록 하겠습니다.
[
{
"object": "block",
"type": "paragraph",
"paragraph": {
"rich_text": [{ "type": "text", "text": { "content": "You made this page using the Notion API. Pretty cool, huh? We hope you enjoy building with us." } }]
}
}
]
이 세 가지 파라미터를 모두 사용해 엔드포인트에 요청을 전송하여 페이지를 생성해 보도록 하겠습니다.
curl -X POST https://api.notion.com/v1/pages \
-H 'Authorization: Bearer '"$NOTION_API_KEY"'' \
-H "Content-Type: application/json" \
-H "Notion-Version: 2021-05-13" \
--data '{
"parent": { "database_id": "494c87d0-72c4-4cf6-960f-55f8427f7692" },
"properties": {
"title": {
"title": [{ "type": "text", "text": { "content": "A note from your pals at Notion" } }]
}
},
"children": [
{
"object": "block",
"type": "paragraph",
"paragraph": {
"text": [{ "type": "text", "text": { "content": "You made this page using the Notion API. Pretty cool, huh? We hope you enjoy building with us." } }]
}
}
]
}'
* 토큰과 ID 정보는 적절히 수정되어야 합니다.
* API 요청에는 크기 제한이 존재합니다. 자세한 내용은 Size Limit를 확인해 주세요.
페이지가 추가되면 새 페이지 객체가 포함된 응답을 받게 됩니다. Notion을 살펴보고 새 페이지를 확인해 보세요.
5. 페이지에서 블록 읽어오기.
페이지 콘텐츠는 자식 블록 검색 엔드포인트를 이용해 읽어올 수 있습니다. 이 엔드포인트는 모든 자식 목록을 반환합니다. 페이지는 블록 자식을 읽어오기 위한 일반적인 시작 방법이지만 다른 종류의 블록에 대한 자식들도 검색할 수 있습니다.
"block_id" 파라미터는 블록의 ID를 의미합니다. 예시에 따른다면 응답에 페이지 ID가 포함되어 있을 것입니다. 해당 페이지의 ID를 "block_id"로 사용해 페이지에서 샘플 콘텐츠를 읽어오도록 하겠습니다.
페이징 된 응답을 받을 수 있습니다. 페이징 된 응답은 Notion API 전반에서 사용됩니다. 페이징 된 응답의 최대 결과 개수는 100개입니다. "start_cursor"과 "page_size" 파라미터를 통해 100개가 넘는 결과를 얻어올 수도 있습니다.
이 응답에서 요청한 자식 블록은 "results" 배열 내부에 존재하게 됩니다.
6. 중첩된 블록 읽어오기.
결과 자체에 자식이 포함된 블록이 있는 경우 어떤 일이 일어날까요? 이 경우 응답에 중첩된 블록이 포함되지는 않지만 "has_children"의 값은 true가 됩니다. 통합에 페이지 콘텐츠 혹은 모든 블록의 완전한 표현이 필요하다면 "has_children"이 true인 블록에 대해 결과를 검색하고 엔드포인트를 재귀적으로 호출해야 합니다.
큰 페이지를 읽는데 다소 시간이 걸릴 수 있습니다. 아키텍처에서 작업 대기열과 같은 비동기 작업을 사용하는 것이 좋습니다. 또한 요청 제한에 도달할 수 있으므로 새 요청을 전송하는 속도를 적절히 늦춰야 할 수도 있습니다.
7. 페이지에 블록 추가하기.
통합은 블록 자식 추가 엔드포인트를 사용해 더 많은 콘텐츠를 추가할 수도 있습니다. 예시에서 만든 페이지에 다른 블록을 추가해 보도록 하겠습니다. 이 엔드포인트에는 "block_id"와 "children"의 두 개의 파라미터가 필요합니다
"block_id"는 기존 블록의 ID입니다. 블록 ID에 앞선 예시에서 사용한 페이지 ID를 동일하게 사용하도록 합니다.
"children" 파라미터는 추가할 내용을 설명할 블록 객체 목록입니다. 더 만든 샘플 콘텐츠를 사용해 보도록 하겠습니다.
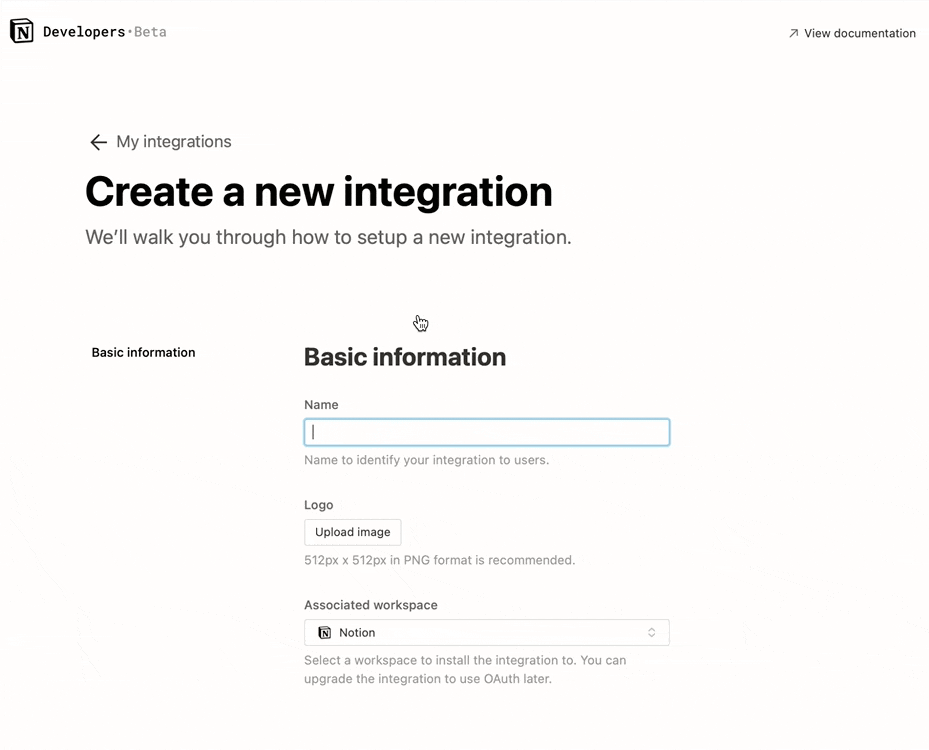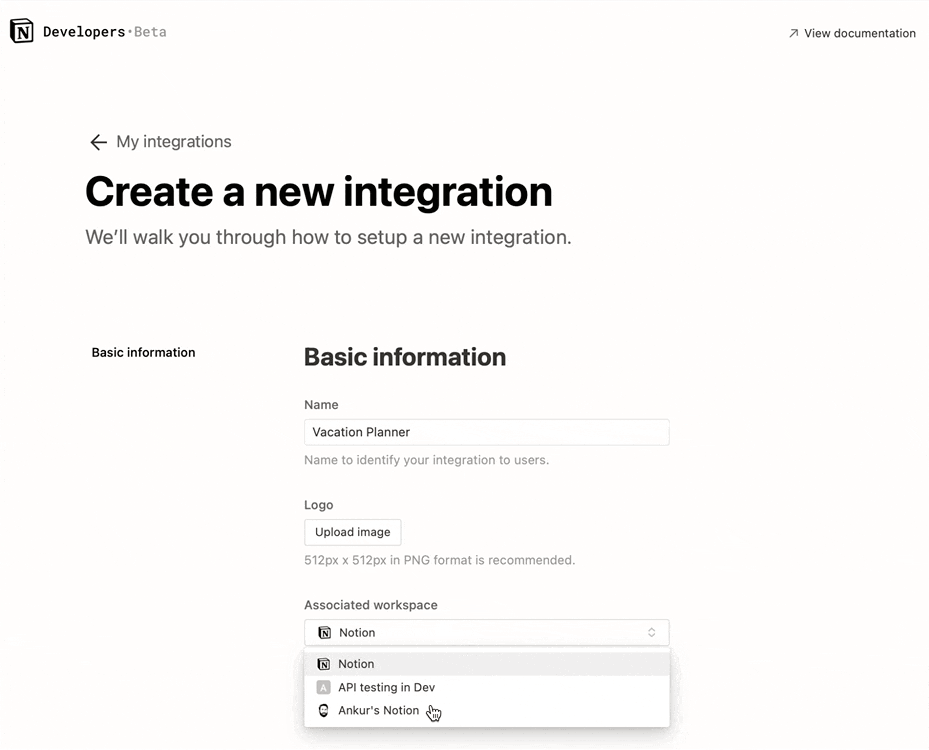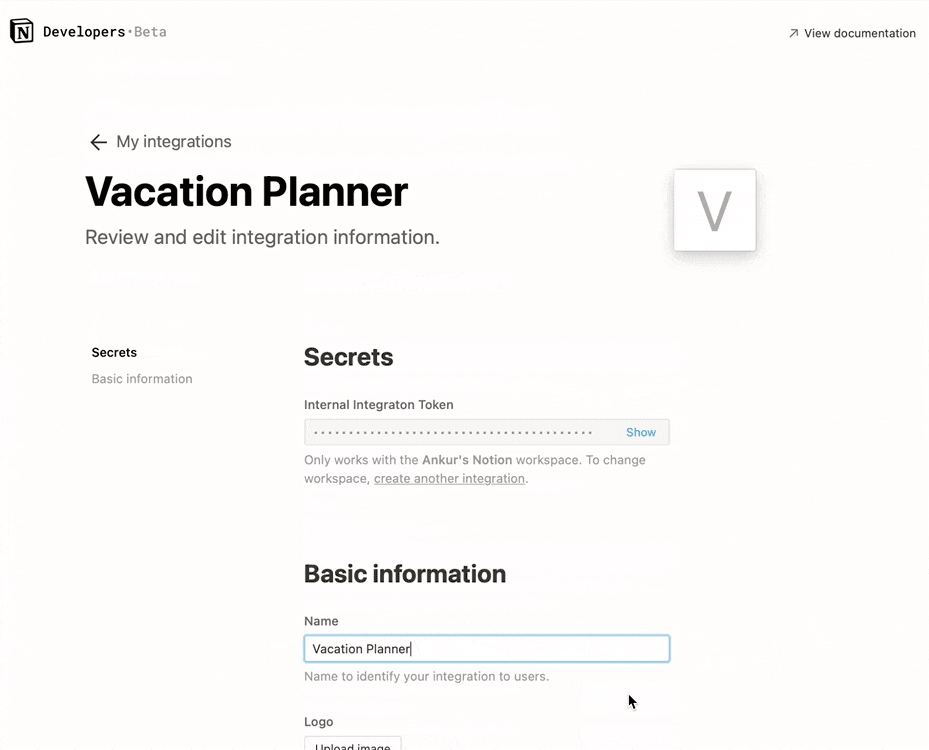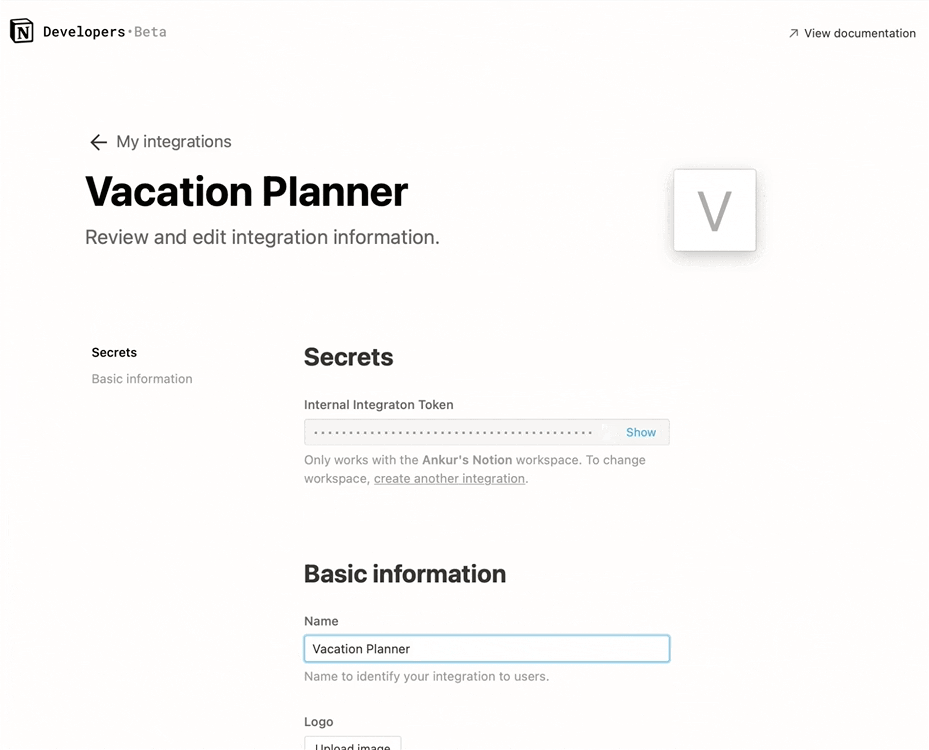
시크릿 아래에서 내부용 통합 토큰을 찾을 수 있습니다. 이 토큰을 표시하도록 하고 복사해두세요. 텍스트 에디터와 같은 나중에 쉽게 찾을 수 있는 곳에 붙여 넣어 둡시다.
4. 통합을 사용해 데이터베이스 공유.
API로 구축된 통합은 사용자에 공유 권한과 유사한 권한 시스템을 따릅니다. 여기에는 중요한 차이점이 있습니다. 통합은 처음엔 워크스페이스의 페이지나 데이터베이스에 액세스 할 수 없습니다. API를 통해 해당 페이지에 액세스 하려면 사용자가 특정 페이지를 통합에 공유해야 합니다. 이런 방식으로 Notion에서 사용자와 팀의 정보를 안전하게 보호할 수 있습니다.
워크스페이스의 새 페이지 또는 기존 페이지에서 시작해봅시다. /표 혹은 /table을 입력하여 새 데이터베이스를 추가합니다. 제목을 정해줍니다. 이 예시에서는 "Weekend getaway destinations"라고 정했습니다. 이제 공유 버튼을 클릭해 실렉터에서 통합을 찾아 선택한 뒤 초대를 클릭합니다.
이제 통합에 새 데이터베이스를 읽고 쓰고 편집할 수 있는 권한이 부여되었습니다. 통합이 워크스페이스에 추가되면 모든 구성원과 통합이 같이 페이지 및 데이터베이스를 공유할 수 있습니다. 이 단계에서는 관리자 권한이 요구되지 않습니다.
계속하기 전에 방금 만든 데이터베이스의 ID를 알아보도록 합시다.
Notion 데스크톱 앱을 사용하는 경우 공유 버튼을 다시 한번 클릭해 링크 복사를 선택합니다. 브라우저에 이 URL을 붙여 넣고 확인하세요. 이 URL에서 데이터베이스 ID는 워크스페이스 이름 슬래시(/) 뒤부터 물음표(?) 앞까지입니다. 데이터베이스 ID는 문자와 숫자를 포함하는 32자입니다. 이 ID를 복사해 나중에 쉽게 찾을 수 있는 곳에 저장해 두세요.
https://www.notion.so/myworkspace/a8aec43384f447ed84390e8e42c2e089?v=... |-------------------- Database ID ------------------|
5. 데이터베이스에 아이템 추가하기.
Notion 데이터베이스에서 각각의 아이템은 자식 페이지입니다. 부모를 데이터베이스로 설정함으로써 새 페이지를 생성해 데이터베이스에 아이템을 추가할 수 있습니다. 새 아이템을 추가하기 위해 페이지 생성 엔드포인트에 HTTP 요청을 보내봅시다.
터미널 프로그램을 열고 다음 커맨드를 입력하세요. Authorization와 database_id의 값은 앞서 생성한 적절한 값으로 변경되어야 합니다. 줄 끝에 보이는 문자(\) 뒤에 공백이 없어야 함을 주의하세요.
커맨드를 실행하고 Notion으로 이동해 새 항목이 데이터베이스에 추가되었는지 확인하세요.
이제 Notion API를 사용해 데이터베이스에 새 항목을 추가했습니다. 커맨드와 함께 보낸 HTTP 요청에 대해 좀 더 자세히 살펴보겠습니다.
* Notion API는 REST API 규칙을 따릅니다.
* 토큰은 Authorization 헤더에 포함되며 요청의 출처를 식별합니다.
* Notion API의 각 엔드포인트는 파라미터를 사용해 호출할 수 있습니다. 엔드포인트의 참고 페이지에는 이러한 파라미터에 대해 설명되어 있습니다. 이 예시에서 parent와 properties는 모두 본문에 명시되어 있습니다. 데이터베이스 작업 가이드에는 다른 엔드포인트를 사용하는 방법에 대해 설명되어 있습니다,
6. 마무리
방금 배운 내용을 사용하면 다른 서비스와 시스템을 연결해 새로운 정보를 Notion에 보내거나 업데이트 해 여러분의 팀이 정보를 확인하고 조치를 취할 수 있도록 합니다.
이 가이드에서는 CURL 명령어를 통해 Notion API에 HTTP 요청을 보내는 방법을 사용하였습니다. 일반적으로 통합은 프로그래밍 언어를 사용하여 코드로 작성될 것입니다. 거의 모든 프로그래밍 언어를 사용할 수 있지만 통합을 사용한 코드를 실행하는데 가장 쉽고 빠른 방법을 찾고 있다면 이 예제를 사용해 보세요. 숙련된 프로그래머들에게도 이 예제는 훌륭한 시작점이 될 것입니다.
여러분이 보고 있는 데이터베이스가 표라고 가정해 보도록 합시다. 속성 객체는 열에 있는 모든 값들의 타입을 포함하며 열에 대한 설명을 저장합니다. 텍스트, 숫자, 날짜, 사람 등의 일반적인 타입을 사용할 수 있으며 각 타입에 대한 추가 구성 또한 사용할 수 있습니다. 다음 데이터베이스 객체 예시를 통해 속성 섹션에 대해 알아보도록 하겠습니다.
이 데이터베이스 객체에는 세 가지 속성이 정의되어 있습니다. 각각의 키는 속성의 이름이며 그 값은 속성 객체입니다. 몇 가지 핵심 사항에 대해 알아보겠습니다.
* "title"은 특별한 타입입니다. 모든 데이터베이스에는 "title" 타입을 가진 딱 하나의 속성이 존재합니다. 이 타입의 속성은 데이터베이스에서 각각의 아이템에 대한 페이지 제목을 참조하게 됩니다. 이 예시에서는 "Grocery item" 속성에 이 "title" 타입이 있습니다.
* "type"의 값은 속성 객체의 또 다른 키에 해당됩니다. 각 속성 객체에는 "type"의 값과 동일한 이름의 속성이 존재합니다. 예를 들어 "Last ordered"에는 "type"에 "date"라는 값이 존재하고 "date" 속성도 존재합니다. 이 패턴은 Notion API 전체에서 사용되며 type-specific 데이터라고 합니다.
* 특정 속성 객체에는 추가 구성이 있습니다. "number" 속성 내부에는 추가 구성이 있는 것을 확인할 수 있습니다. 이 예시에서 포맷 설정은 이 열이 보이는 방식을 제어하며 "dollar"로 설정되었습니다.
3. 데이터베이스에 페이지 추가하기.
페이지는 데이터베이스 내부의 아이템으로 사용되며 각 페이지의 속성은 부모 데이터베이스의 스키마를 따라야 합니다. 데이터베이스를 표라고 가정하면 페이지의 속성들은 한 행의 모든 값을 정의합니다.
페이지는 페이지 생성 API의 엔드포인트를 사용해 데이터베이스에 추가됩니다. 이 예시에서 데이터베이스에 새 페이지를 추가해 보도록 하겠습니다. 엔드포인트는 "parent"와 "properies"라는 두 가지 파라미터가 요구됩니다.
데이터베이스에 페이지를 추가할 때 "parent" 파라미터는 데이터베이스가 되어야 합니다.
페이지가 추가된다면 새 페이지 객체가 포함된 응답을 받게 됩니다. 이 응답에서 중요한 속성은 페이지 ID입니다. Notion을 외부 시스템에 연결하여 사용하는 경우 이 페이지 ID를 알아두는 것이 좋습니다. 나중에 이 페이지의 속성을 업데이트할 때 업데이트 페이지 엔드포인트에서 이 ID를 사용합니다.
4. 데이터베이스에서 페이지 찾기.
데이터베이스 쿼리 엔드포인트를 사용해 데이터베이스에서 페이지를 읽어올 수 있습니다. 이 엔드포인트를 사용하려면 "Last ordered가 지난주부터"와 같은 기준에 따라 페이지를 찾을 수 있습니다. 일부 큰 데이터베이스에서는 이 엔드 포인트를 사용하면 특정 순서의 더 작은 결과를 얻어 낼 수 있습니다.
이렇게 페이지를 찾는 데 사용되는 조건을 필터라고 합니다. 필터는 "Tag에 긴급이 포함됨"과 같은 단순한 조건부터 "Tag에 긴급이 포함되어야 하고 Due date는 몇 주 이내여야 하며 Assignee는 Cassandra Vasquez여야 함"과 같은 복잡한 조건으로 설정할 수 있습니다. 이러한 복잡한 조건은 "and"나 "or"을 사용해 여러 개의 단순한 조건을 결합하여 사용하므로 복합필터라고 합니다.
이 가이드에서는 예시 데이터베이스에 단일 속성 조건을 사용하는 것을 중점으로 둡니다. 데이터베이스 스키마를 살펴보면 "Last ordered" 속성이 "date" 타입을 사용한다는 것을 알고 있습니다. 즉 "date" 타입에 대한 조건을 사용해 "Last ordered"에 대한 필터를 만들 수 있습니다.
사실 이 응답은 페이징 된(paginated) 응답입니다. 페이징 된 응답은 큰 객체 목록을 반환하는 모든 Notion API의 응답에 사용됩니다. 페이징 된 응답의 최대 결과 개수는 100개입니다. 페이징 된 결과는 "start_cursor"과 "page_size" 파라 미터를 사용해 100개 이상의 결과를 얼어올 수도 있습니다.
이 예시에서 요청한 개별 페이지에 대한 정보는 "results"에 있습니다. 통합이나 사용자가 최근에 만들어진 페이지에 관심이 있다면 어떨까요? 가장 최근에 생성된 페이지가 첫 번째로 오도록 결과를 정렬할 수 있습니다. 특히 결과 페이지가 하나가 아닌 경우에 유용합니다.
"sort" 파라미터는 개별 속성 혹은 타임스탬프에 의해 결과를 정렬하는 데 사용됩니다. 이 파라미터는 정렬 객체의 배열에 할당될 수 있습니다.
페이지가 생성된 시간은 데이터베이스 스키마를 따르는 페이지 속성이 아닙니다. 이 속성은 모든 페이지에 존재는 두 종류의 타임스탬프 중 하나입니다. 이를 "created_time" 타임스탬프라고 합니다.
이제 가장 최근에 생성된 페이지가 먼저 표시되도록 결과를 정렬하는 정렬 객체를 만들어보도록 하겠습니다.
Docker, Express, NGINX, AWS ELB를 복합적으로 사용해 고가용성을 위한 애플리케이션 환경을 구축해 봅니다.
로드 밸런싱이 무엇인가요?
로드 밸런싱은 들어오는 네트워크 트래픽을 서버 그룹에 분산하는 데 사용되는 기술 혹은 알고리즘입니다. 모든 공용 사용자에게 서버에서 호스팅 하는 서비스에 대한 단일 진입점을 제공합니다.
프로덕션 서버는 일반적으로 로드 밸런서 뒤에서 실행됩니다. 서버 전체에서 들어오는 부하를 "균등"하게 나워 서버 과부하를 방지할 수 있기 때문입니다.
또한 로드 밸런서는 트래픽을 라우팅 하는 서버에 보조 기능을 제공합니다. 로드 밸런서는 역방향 프락시 역할을 합니다. 역방향 프락시는 서버 그룹과 사용자 간의 중개자와 같습니다. 역방향 프락시가 처리하는 모든 요청은 요청 조건에 따라 적절한 서버로 전달됩니다. 이런 방식으로 역방향 프락시는 구성파일, 토큰, 암호와 같은 민감한 데이터가 저장되는 주 서버에 대한 액세스를 방지하면서 서버의 ID를 익명으로 유지합니다.
로드 밸런서로서의 NGINX와 AWS ELB
NGINX는 역방향 프락시의 역할도 할 수 있는 빠른 무료 오픈소스 로드 밸런서입니다.
반면에 ELB는 아마존 AWS에서 제공하는 로드 밸런싱 서비스입니다. ELB는 ALB, CLB, NLB의 세 가지 유형이 있습니다. 게이트웨이 로드 밸런서라고 하는 새로운 로드 밸런서도 AWS가 제공하는 클라우드 서비스 제품군에 추가되었습니다.
이 튜토리얼의 아이디어는 다중 포트에서 실행되는 고 가용성 Node.js 서버를 제공할 수 있는 계단식의 다중 로드 밸런서 구조를 만드는 것입니다.
* 참고사항
Docker 애플리케이션을 위해 AWS의 자체 ECS, ECR 환경을 활용하는 방법을 포함해 AWS에서 Node.js 애플리케이션을 위한 인프라를 구축하는 방법에는 여러 가지 방법이 있습니다. 하지만 이 자습서에서는 이에 초점을 맞추지 않고 EC2 인스턴스, 로드 밸런서의 메커니즘, 로드밸런싱, 프락시 포트를 통해 Docker와 상호작용 하는 방법을 더 잘 이해하는 것을 목표로 합니다.
아키텍처 개요
이것이 우리가 목표로 하는 아키텍처입니다. AWS와 NGINX에서 관리하는 다중 로드 밸런서는 node 앱을 위한 EC2 인스턴스에서 여러 포트를 관리하는데 도움이 됩니다. 이 아키텍처의 장점은 두 인스턴스가 AZ1과 AZ2의 서로 다른 가용 영역을 가진다는 것입니다. 이로 인해 한 영역이 다운되더라도 다른 영역은 계속 동작할 것이며 두 애플리케이션은 충돌하지 않게 됩니다.
앱 폴더에는 Dockerfile과 함께 노드 서버 소스 코드가 포함되어 있습니다. nginx 폴더에는 업스트림 서버 포트 구성을 정의하는 구성 파일인 nginx.conf가 있으며 다음과 같습니다:
http{
upstream lb {
server 172.17.0.1:1000 weight=1;
server 172.17.0.1:2000 weight=1;
server 172.17.0.1:3000 weight=1;
}
server {
listen 80;
location / {
proxy_pass http://lb;
}
}
}
이 구성 파일은 메인 NGINX 서버가 포트 80번에서 동작한다고 지정하고 루트 위치 "/"은 lb라는 이 구성 파일에 정의된 업스트림으로 요청(프락시 패스)을 릴레이 합니다. lb는 서버 수를 지정하는 업스트림 객체이며 이 객체는 포함될 서버의 수와 이러한 서버가 내부적으로 실행될 포트를 지정합니다. 여기서 포함될 서버란 docker-compose를 통해 마운트 되는 서버이며 이는 이후 섹션에서 좀 더 자세히 다룹니다. 프락시는 80번 포트의 트래픽 부하를 분산시키게 됩니다.
우리의 경우 업스트림 프락시는 트래픽을 1000번, 2000번, 3000번 포트로 보냅니다. 이 포트 번호는 docmer-compose YAML 파일에서 작성되는 env 변수로 익스프레스 서버 인스턴스에 전송되는 내부 PORT 값과 일치해야 합니다.
각각의 시작되는 인스턴스에 대해 다음 작업을 수행해 줍니다.
1. 생성했던 키 페어를 이용해 인스턴스에 SSG로 연결합니다.
2. 다음 터미널 명령을 수행해 dockerfile로 앱 이미지를 빌드합니다.
git clone https://github.com/sowmenappd/load_balanced_nodejs_app.git
cd load_balanced_nodejs_app/app
docker build -t app .
3. 다음으로 NGINX 서버 이미지를 빌드합니다.
cd ../nginx
docker build -t nginx-s .
4. docker images 명령어를 실행 해 다음과 같은 내용이 표시되는지 확인합니다.
5. 두 번째 서버는 docker-compose.yml 파일을 수정해야 합니다. env 변수중 SERVER_ID는 모든 앱인 app1, app2, app3에 대해 2로 변경해야 합니다.
걱정하지 마세요 프로덕션 서버에서는 이런 일을 할 필요가 없습니다. 이는 데모 목적만을 위한 것입니다.
6. 마지막으로 다음 명령어를 실행합니다.
cd ..
docker-compose up -d
격리된 서버는 이제 백그라운드에서 세 개의 express 앱을 실행하게 됩니다. 이제 필요한 것은 AWS가 제공하는 로드 밸런서인 AWS ALB를 사용하여 이 시스템을 마운트 하는 것입니다.
AWS ALB에 시스템 마운트 하기.
이제 두 인스턴스 모두 마운트 할 준비가 되었습니다. 다음 단계를 따라 AWS에 애플리케이션 로드 밸런서를 설정하도록 합시다.
1. EC2 대시보드의 대상 그룹으로 이동해 대상 그룹을 만듭니다.
2. 대상 유형은 인스턴스를 선택 한 뒤 대상 그룹 이름을 작성하고 다음을 클릭하세요.
3. 실행 중인 두 인스턴스를 선택하고 선택한 인스턴스를 위한 포트를 80으로 설정한 뒤 아래에 보류 중인 것으로 포함 버튼을 클릭합니다.
4. 보류 중인 항목에 추가된 인스턴스를 확인한 뒤 대상 그룹을 생성합니다.
5. 이제 로드 밸런서로 이동해 로드 밸런서 생성 버튼을 클릭한 뒤 Application Load Balancer 생성을 클릭합니다.
6. 앞서 인스턴스를 생성할 때 선택한 가용 영역을 고른 뒤 계속합니다.
7. 보안 그룹 구성으로 이동해 모든 IP에 대해 80번 포트가 열려있는 새 보안 그룹을 만들고 다음을 클릭합니다.
8. 라우팅 구성에서 앞서 기존 대상 그룹을 고른 뒤 앞서 생성한 대상 그룹을 선택합니다.
9. 설정을 검토 한 뒤 로드 밸런서를 생성합니다. 로드 밸런서는 생성 후 상태 확인을 실행 한 뒤 몇 분 내로 실행되어야 합니다.
이제 EC2 대시보드의 로드 밸런서에서 방금 생성한 로드 밸런서의 DNS이름을 복사합니다.
이 DNS 주소를 브라우저에 붙여 넣고 엔터를 누르세요. 브라우저를 새로 고칠 때마다 SERVER_ID와 PORT가 다른 값을 전송하는 것을 볼 수 있습니다.
이는 기본적으로 NGINX와 AWS 로드 밸런서가 로드 밸런싱을 위해 기본적으로 라운드 로빈 알고리즘을 사용하기 때문입니다.
맺는 글.
이렇게 배포된 시스템은 다중 로드 밸런서의 구성을 통해 높은 가용성을 보장하고 오랜 기간 동작하는 동안 많은 양의 트래픽을 견딜 수 있게 되었습니다. 이 자습서를 뒤이어 소스 제어와 통합 배포 파이프라인을 관리하고 GitHub 저장소에 커밋할 때 변경사항을 서버에 배포하는 방법을 보여주는 또 다른 기사를 게시할 예정입니다.
NGINX는 웹 서비스, 역방향 프록시, 캐싱, 로드밸런싱, 미디어 스트리밍등을 위한 오픈소스 소프트웨어 입니다. 이 글에서는 자주 사용하는 NGINX 구성을 몇가지 다루도록 하겠습니다.
1. Listen To Port
server {
# Standard HTTP Protocol
listen 80;
# Standard HTTPS Protocol
listen 443 ssl;
# Listen on 80 using IPv6
listen [::]:80;
# Listen only on using IPv6
listen [::]:80 ipv6only=on;
}
2. Access Logging
server {
# Relative or full path to log file
access_log /path/to/file.log;
# Turn 'on' or 'off'
access_log on;
}
3. Domain Name
server {
# Listen to yourdomain.com
server_name yourdomain.com;
# Listen to multiple domains
server_name yourdomain.com www.yourdomain.com;
# Listen to all domains
server_name *.yourdomain.com;
# Listen to all top-level domains
server_name yourdomain.*;
# Listen to unspecified Hostnames (Listens to IP address itself)
server_name "";
}
server {
listen 80;
server_name yourdomain.com;
location / {
proxy_pass http://0.0.0.0:3000;
# where 0.0.0.0:3000 is your application server (Ex: node.js) bound on 0.0.0.0 listening on port 3000
}
}
7. Load Balancing
upstream node_js {
server 0.0.0.0:3000;
server 0.0.0.0:4000;
server 123.131.121.122;
}
server {
listen 80;
server_name yourdomain.com;
location / {
proxy_pass http://node_js;
}
}
이제 도커 이미지로 빌드해 봅시다. 자동으로 생성된 Dockerfile을 우클릭 해 Docker 이미지 빌드를 클릭합니다.
정상적으로 빌드되는지 확인합니다. 해당 방식으로 이미지를 빌드하면 자동으로 latest 태그가 설정되어 빌드가 됩니다.
3. fluentd 추가하기.
앞서 작성한 프로그램이 로그를 남기면 fluentd는 그 로그파일을 읽어 Elasticsearch로 로그를 전송하는 역할을 담당하게 될 겁니다. 이렇게 로그 파일을 추적해 로그를 전송하는 방식은 fluentd의 "tail" Input Plugin을 사용합니다. 자세한 내용은 공식 홈페이지를 참고해 주시기 바랍니다: Fluentd - tail
로그를 읽어 들이는 Input Plugin이 있으면 반대로 읽은 로그를 Elasticsearch로 전송하는 기능도 있습니다. 다행히도 별도의 구현을 할 필요 없이 바로 Elasticsearch로 로그를 보낼 수 있도록 Elasticsearch Output Plugin을 제공해주고 있습니다. 자세한 내용은 공식 홈페이지를 참고해 주시기 바랍니다: Fluentd - elasticsearch
이제 tail과 elasticsearch를 사용할 수 있도록 fluentd의 설정 파일을 작성하도록 하겠습니다.
앞서 작성한 프로그램의 로그를 읽어 elasticsearch로 전송하는 설정 파일입니다. 다음으로는 이 설정 파일과 elasticsearch 플러그인을 사용할 수 있도록 fluentd 이미지를 빌드하는 dockerfile을 작성합니다.
# /fluentd/dockerfile
FROM fluentd:v1.9.1-debian-1.0
COPY /conf/* /fluentd/etc/
USER root
RUN ["gem", "install", "fluent-plugin-elasticsearch", "--no-document", "--version", "4.3.3"]
USER fluent
이제 이 dockerfile을 사용해 fluentd 이미지를 빌드해 줍니다.
$ docker build . -t my-fluentd:0.0.1
** 여기서는 conf 파일을 포함하는 이미지를 미리 빌드해서 사용합니다.
** 만약 docker-compose에서 새로 빌드하고자 한다면 dockerfile의 "COPY /conf/* /etc/"를 사용할 수 없으므로 별도로 conf 파일을 옮겨주는 작업이 필요합니다.
4. 배포를 위한 docker-compose 작성.
이 글은 간단한 테스트를 위한 글이므로 테스트 프로그램, fluentd, Elasticsearch, Kibana 모두 한 docker-compose 파일 내에 작성해 배포하도록 진행하겠습니다.
내용은 간단합니다. 앞서 빌드한 이미지인 fluentdtester:latest와 my-fluentd:0.0.1 그리고 elasticsearch와 kibana를 실행시킵니다. fluentd-tester와 fluentd 서비스는 test-logs라는 이름의 볼륨을 이용해 데이터를 공유하도록 해주었습니다.
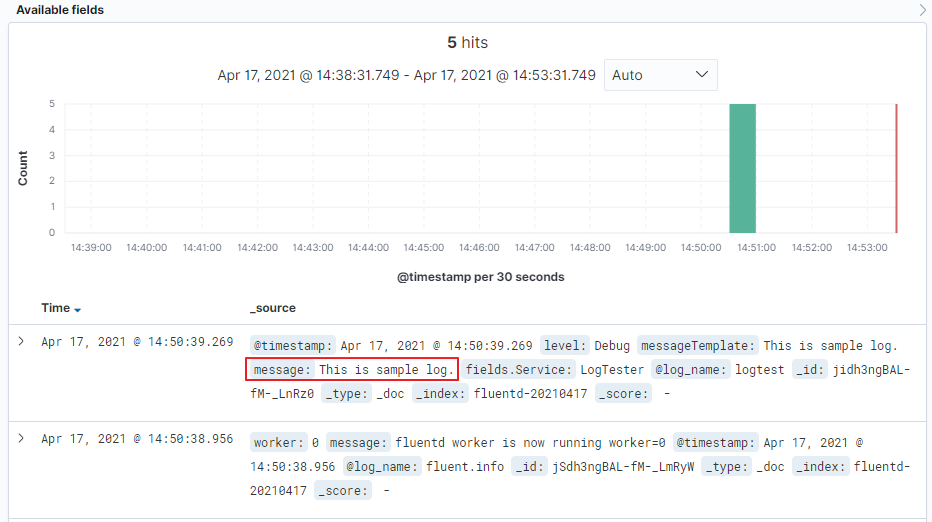
이를 통해 fluentd-service에서 작성한 로그파일에 fluentd가 접근해 tail로 로그파일을 elasticsearch로 전송합니다.
다음 명령어를 통해 docker-compose를 실행시켜봅시다.
$ docker-copmpose up -d
정상적으로 컨테이너들이 실행된 것을 확인할 수 있습니다.
5. 동작 확인.
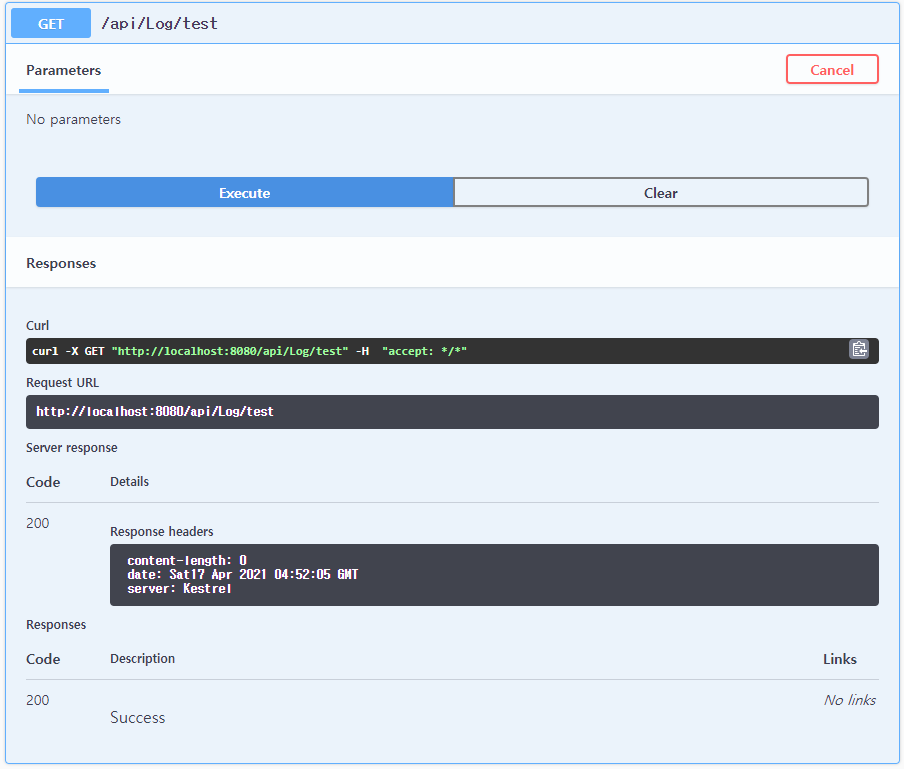
컨테이너가 정상적으로 실행되었다면 이제 테스트 로그를 남겨봅시다. 다음 주소로 이동해 swagger를 사용해 로그를 남깁시다.
mongo2와 mongo3은 mongo 이미지를 그대로 가져와 사용합니다. 볼륨은 각각 자신이 설정한 볼륨 경로 내의 "mongoRepl/mongo2"와 "mongoRepl/mongo3"에 컨테이너 내부의 mongodb 데이터가 저장됩니다.
세 컨테이너는 depends_on으로 연결되어 있으며 bridge 네트워크를 사용해 서로 서비스 이름을 통해 통신할 수 있습니다. 추가적으로 mongo2와 mongo3은 replSet 명령어로 "replication"이라는 이름으로 ReplicaSet을 생성합니다. 이 이름은 앞서 작성한 js의 _id에 입력한 값과 동일해야 합니다.
mongo1은 다른 두 서비스와 달리 mongo 이미지를 그대로 사용하지 않고 앞서 작성한 dockerfile을 이용해 새로운 이미지를 빌드합니다. 이 서비스가 실행되면 다른 두 mongodb 서비스와 같이 ReplicaSet을 구성하게 됩니다.
이제 다음 명령어를 통해 docker-compose를 실행시켜 봅시다
$ docker-compose up -d
이제 ReplicaSet이 정상적으로 동작하는지 확인하기 위해 컨테이너에 접속해 봅시다. 먼저 컨테이너의 ID를 확인합니다.
$ docker ps -a
컨테이너 ID를 확인 후 아무 데나 접속해 봅니다.
$ docker exec -u 0 -it 51 mongo
위와 같이 "replication:PRIMARY" 혹은 "replication:SECONDARY"라고 표시되면 정상적으로 ReplicaSet이 구성된 겁니다.
Visual studio 2019의 다른 여러가지 Web 프로젝트는 대부분 기본적으로 Docker Container 배포를 지원합니다. 하지만 안타깝게도 포스팅을 올리는 현재 Visual studio 2019에서 React.js 프로젝트는 Docker Container 배포를 기본적으론 지원하지 않습니다. 앞서 프로젝트를 만들 때 docker 지원을 보지 못하셨을 겁니다.
React.js 프로젝트에 수동으로 docker 지원을 추가해 봅시다. 먼저 프로젝트를 우클릭한 뒤 추가 -> Docker 지원을 클릭합니다.
대부분의 경우는 Linux container일겁니다. 자신이 원하는 대상 OS를 선택합니다.
이제 IDE가 자동으로 "Dockerfile"을 생성해 .Net5.0에 맞는 dockerfile을 작성해 줍니다. "Dockerfile"을 우클릭 해 "Docker 이미지 빌드"를 클릭해 도커 이미지를 생성해 봅시다.
빌드가 잘 되시나요? 아마 다음과 같은 오류와 함께 빌드가 실패했을 것입니다.
이제 빌드 출력창을 한번 뒤져봅시다. 아마 다음과 같은 에러 메시지를 마주 할 수 있을 겁니다.
1>#16 2.809 /bin/sh: 2: /tmp/tmp1d7d426dff82428db5f0845ee787658f.exec.cmd: npm: not found 1>#16 2.814 /src/DockerDeployExample/DockerDeployExample.csproj(37,5): error MSB3073: The command "npm install" exited with code 127. 1>#16 ERROR: executor failed running [/bin/sh -c dotnet publish "DockerDeployExample.csproj" -c Release -o /app/publish]: exit code: 1
누가 봐도 어디서 문제가 생긴건지 찾으실 수 있을 겁니다 npm: not found 우리 이미지엔 npm이 없었습니다.
리눅스 컨테이너 항목을 보면 수동으로 nodejs를 설치해야 하는 것을 알 수 있습니다. 이제 우리 "Dockerfile"에 다음과 같은 명령어를 추가해 주도록 합니다.
RUN curl -sL https://deb.nodesource.com/setup_15.x | bash - RUN apt-get install -y nodejs
* 현재 포스팅 일자 기준으로 nodejs의 최신 버전은 15.x 버전이며 LTS는 14.x 버전입니다.
MSDN페이지에선 base와 build 모두에 설치했지만 .Net5.0에선 base 이미지에 nodejs를 설치하면 에러가 발생하며 build 이미지에만 nodejs를 설치해 줘도 정상적으로 빌드가 됩니다.
수정한 Dockerfile은 다음과 같습니다.
#See https://aka.ms/containerfastmode to understand how Visual Studio uses this Dockerfile to build your images for faster debugging.
FROM mcr.microsoft.com/dotnet/aspnet:5.0 AS base
WORKDIR /app
EXPOSE 80
FROM mcr.microsoft.com/dotnet/sdk:5.0 AS build
RUN curl -sL https://deb.nodesource.com/setup_15.x | bash -
RUN apt-get install -y nodejs
WORKDIR /src
COPY ["DockerDeployExample/DockerDeployExample.csproj", "DockerDeployExample/"]
RUN dotnet restore "DockerDeployExample/DockerDeployExample.csproj"
COPY . .
WORKDIR "/src/DockerDeployExample"
RUN dotnet build "DockerDeployExample.csproj" -c Release -o /app/build
FROM build AS publish
RUN dotnet publish "DockerDeployExample.csproj" -c Release -o /app/publish
FROM base AS final
WORKDIR /app
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "DockerDeployExample.dll"]
이제 다시 "Dockerfile"을 우클릭 해 "Docker 이미지 빌드"를 클릭해 도커 이미지를 생성해보면 정상적으로 이미지가 생성되는 것을 확인할 수 있습니다.
4. Docker image push
이제 빌드한 이미지를 "게시" 기능을 이용해 Docker Registry에 Push까지 해봅시다. Docker Registry는 DockerHub를 사용하거나 PrivateRegistry를 구축해 사용하시면 됩니다.