
파이썬을 이용해 RabbitMQ에 메시지를 생성하고 소비하는 방법을 알아봅니다.
1. 사전준비
RabbitMQ를 미리 준비해 둡니다. 로컬에 설치하든 따로 서버를 준비해 설치하든 상관없습니다.
설치 가이드는 다음 글을 참고해 주세요.
2. RabbitMQ 설정
초기 RabbitMQ를 설치하고 나면 vhost와 사용할 queue를 생성해야 합니다.
먼저 vhost를 생성합니다. 로그인 후 Admin > Virtual Hosts로 이동합니다.

Add new virtual host에서 적당한 이름을 입력 한 후 vhost를 생성합니다.

위와 같이 새로운 vhost가 생성된 것을 확인할 수 있습니다. 유저를 보니 아직 vhost에 유저가 하나도 없네요. 생성된 vhost를 클릭해 유저를 할당해 봅시다.

적당한 유저를 고르고 Set permission을 눌러 권한을 부여합니다.
이제 queue 탭으로 이동해 새로운 큐를 생성합니다.

적당한 이름의 queue를 생성해 줍니다. 이 예제에서는 default exchange를 사용할 예정이므로 별도의 exchange는 생성하지 않습니다.
3. PIKA
파이썬으로 AMQP를 이용하기 위해 PIKA를 사용합니다.
Pika는 AMQP 0-9-1 프로토콜의 순수한 Python 구현체로써 기본 네트워크 지원 라이브러리와 독립적으로 유지됩니다.
자세한 내용은 여기서 확인하시기 바랍니다.
4. Publisher 구현
virtualenv를 통해 가상 환경을 생성 한 후 pika를 설치합니다.
> pip install pika
그리고 publisher.py 파일을 생성해 다음과 같이 코딩합니다.
import pika
class Publisher:
def __init__(self):
self.__url = 'host or ip here'
self.__port = 5672
self.__vhost = 'mq_test'
self.__cred = pika.PlainCredentials('id here', 'password here')
self.__queue = 't_msg_q';
return
def main(self):
conn = pika.BlockingConnection(pika.ConnectionParameters(self.__url, self.__port, self.__vhost, self.__cred))
chan = conn.channel()
chan.basic_publish(
exchange = '',
routing_key = self.__queue,
body = 'Hello RabbitMQ'
)
conn.close()
return
publisher = Publisher()
publisher.main()
init에서 필요한 변수를 미리 지정해 둡니다. '만약 로컬에 기본값으로 설치했다면 url에 localhost, port에 5672를 사용하면 됩니다. vhost와 queue는 앞에서 생성 한 대로 입력했습니다. cred는 vhost 액세스 권한이 부여된 계정을 입력하면 됩니다.
코드 내용은 단순합니다. BlockingConnection을 이용해 커넥션을 생성합니다. chan에 생성된 연결에서 채널을 가져 온 후 basic_publish를 이용해 메시지를 발행합니다.
exchange에 빈값을 넣어 default exchange를 사용하도록 하였으며 routing_key에 타겟 큐 이름을 넣었습니다. body엔 메시지 내용을 입력하면 됩니다.
이렇게 한번 실행하면 t_msg_q에 Hello RabbitMQ라는 메시지가 한번 생성되고 종료하는 publisher를 만들었습니다.
실제로 MQ 관리자 페이지에서 queue를 눌러보면 메시지가 들어온 것을 확인할 수 있습니다.
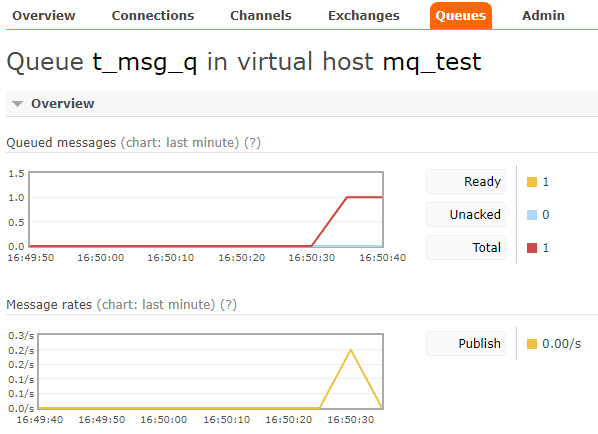
더 아래의 Get messages에서 실제 메시지를 조회 해 볼 수도 있습니다.

5. Consumer 구현
이제 메시지를 발행했으니 소비자를 구현해 보도록 하겠습니다.
별도의 폴더에서 virtualenv를 통해 가상 환경을 생성한 후 pika를 설치합니다.
> pip install pika
그 후 consumer.py 파일을 만들어 다음과 같이 코딩합니다.
import pika
class Consumer:
def __init__(self):
self.__url = 'host or ip here'
self.__port = 5672
self.__vhost = 'mq_test'
self.__cred = pika.PlainCredentials('id here', 'password here')
self.__queue = 't_msg_q';
return
def on_message(channel, method_frame, header_frame, body):
print('Received %s' % body)
return
def main(self):
conn = pika.BlockingConnection(pika.ConnectionParameters(self.__url, self.__port, self.__vhost, self.__cred))
chan = conn.channel()
chan.basic_consume(
queue = self.__queue,
on_message_callback = Consumer.on_message,
auto_ack = True
)
print('Consumer is starting...')
chan.start_consuming()
return
consumer = Consumer()
consumer.main()
publisher와 다른점만 설명하겠습니다.
on_message는 메시지를 수신했을 때 실행 될 콜백 함수입니다. 이 예제에서는 단순히 받은 메시지를 출력하는 역할을 하고있습니다.
채널까지 생성한 후 basic_consume를 통해 메시지를 소비하는 방법을 정의합니다. queue엔 앞서 생성한 큐의 이름을 넣어주면 되고 on_message_callback에는 앞에서 정의한 콜백 함수를 넣어줍니다. auto_ack는 메시지를 소비했을 때 자동으로 ack을 날릴지 여부입니다. ack을 mq에 전송하면 소비된 메시지는 제거됩니다.
그 후 start_consuming()을 실행하면 지속적으로 큐에 있는 메시지를 소비하는 상태가 됩니다. 중단하고 싶으면 Ctrl + C를 눌러 중단하면 됩니다.
이제 파이썬을 실행시키면 다음과 같이 메시지가 출력됩니다.

아까 발행한 메시지를 정상적으로 소비하였습니다. 관리자 페이지로 이동해 보면 auto_ack 옵션에 따라 전송된 ack에 의해 메시지가 삭제된 것을 확인할 수 있습니다.

'Programming > Python' 카테고리의 다른 글
| [Crawler] Python과 BS4를 이용한 크롤러 만들기 - 2 (0) | 2020.02.03 |
|---|---|
| [Crawler] Python과 BS4를 이용한 크롤러 만들기 - 1 (0) | 2020.01.21 |
| [Django] CentOS7 환경에서의 Django 실행 (0) | 2017.06.16 |
| [Django] url expressions (0) | 2017.06.07 |
| [Django] MVC 패턴 (0) | 2017.06.07 |













