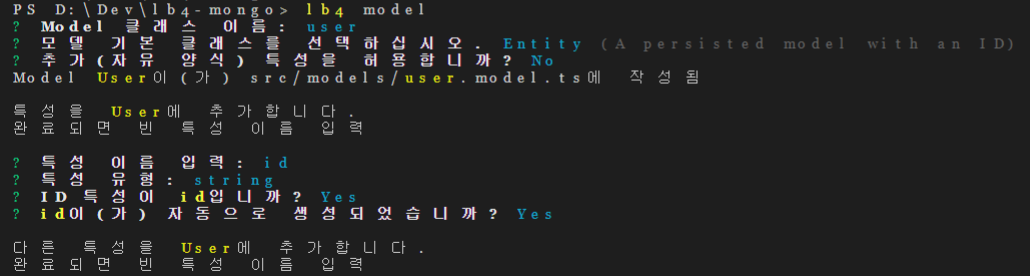
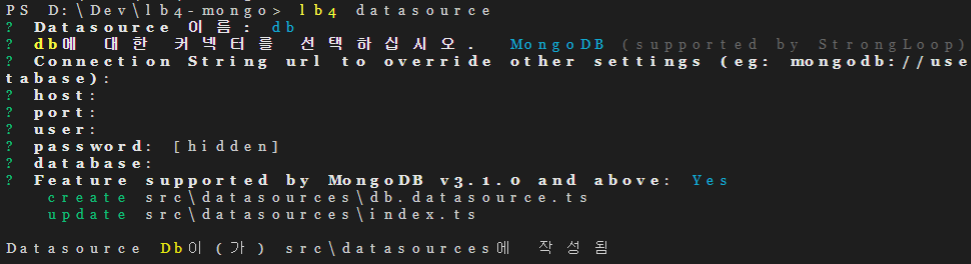
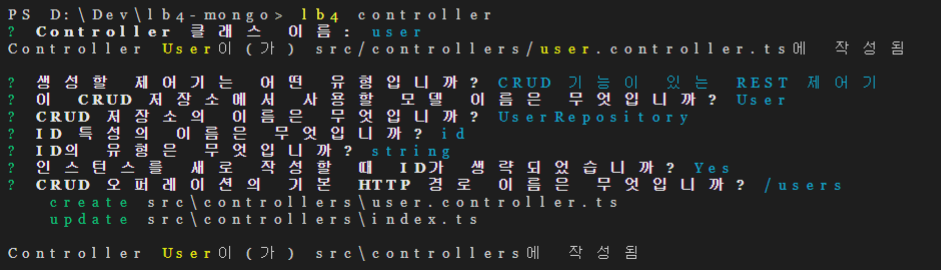
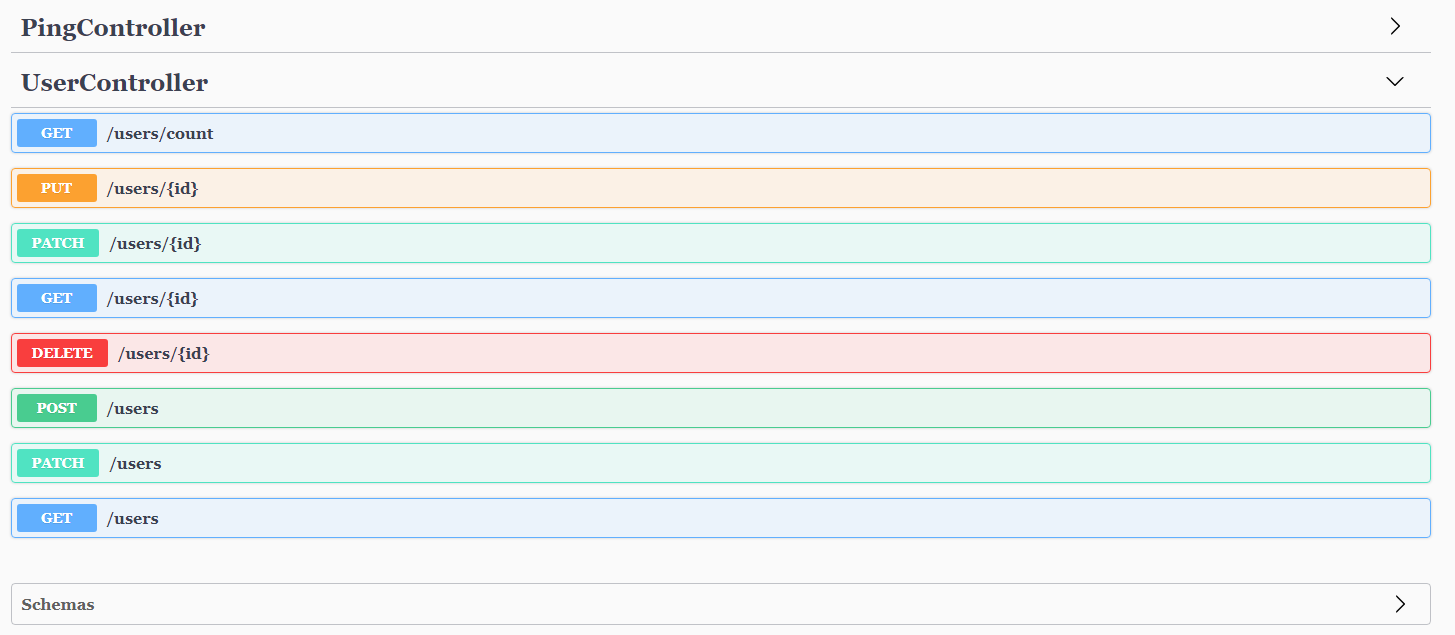
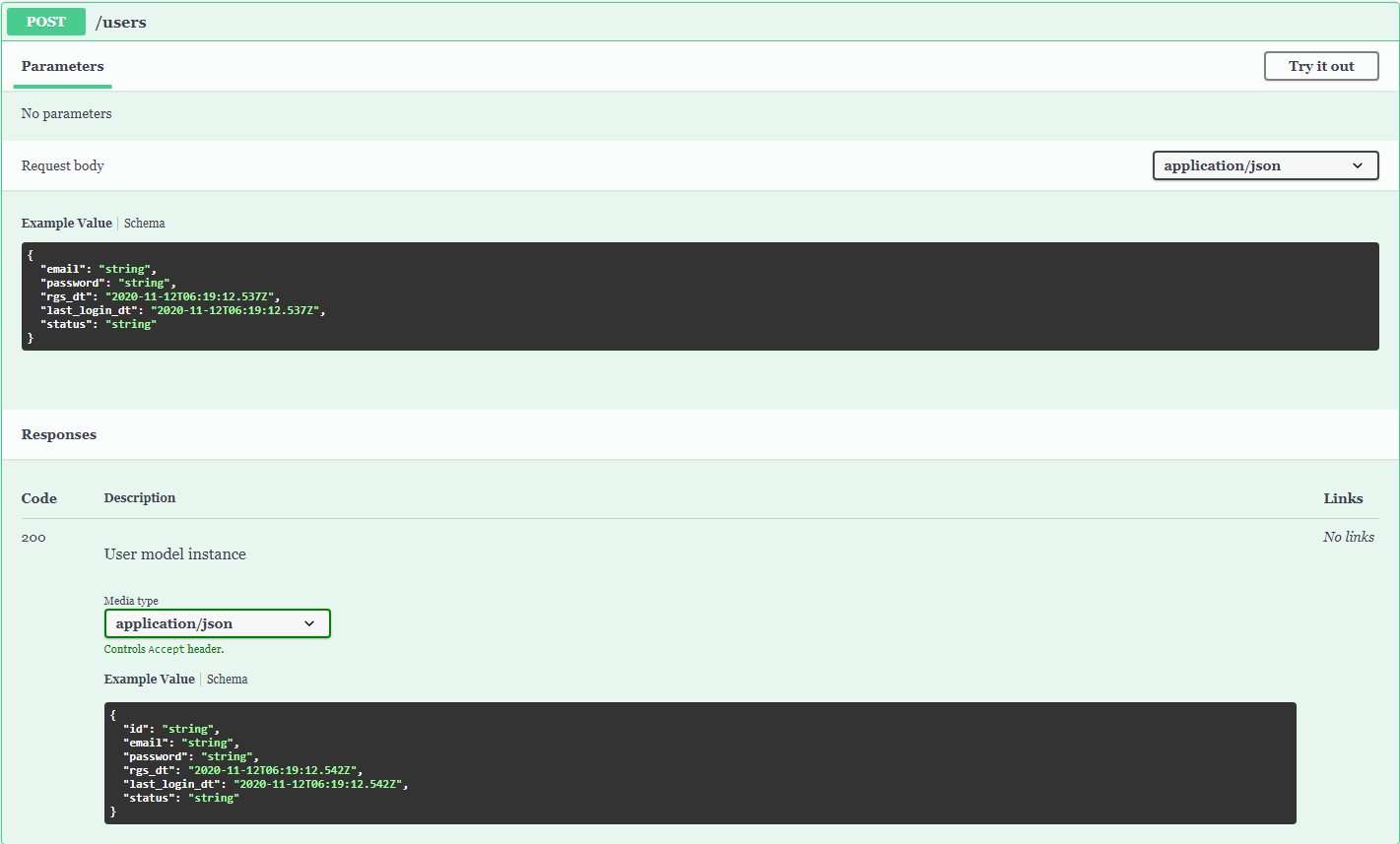
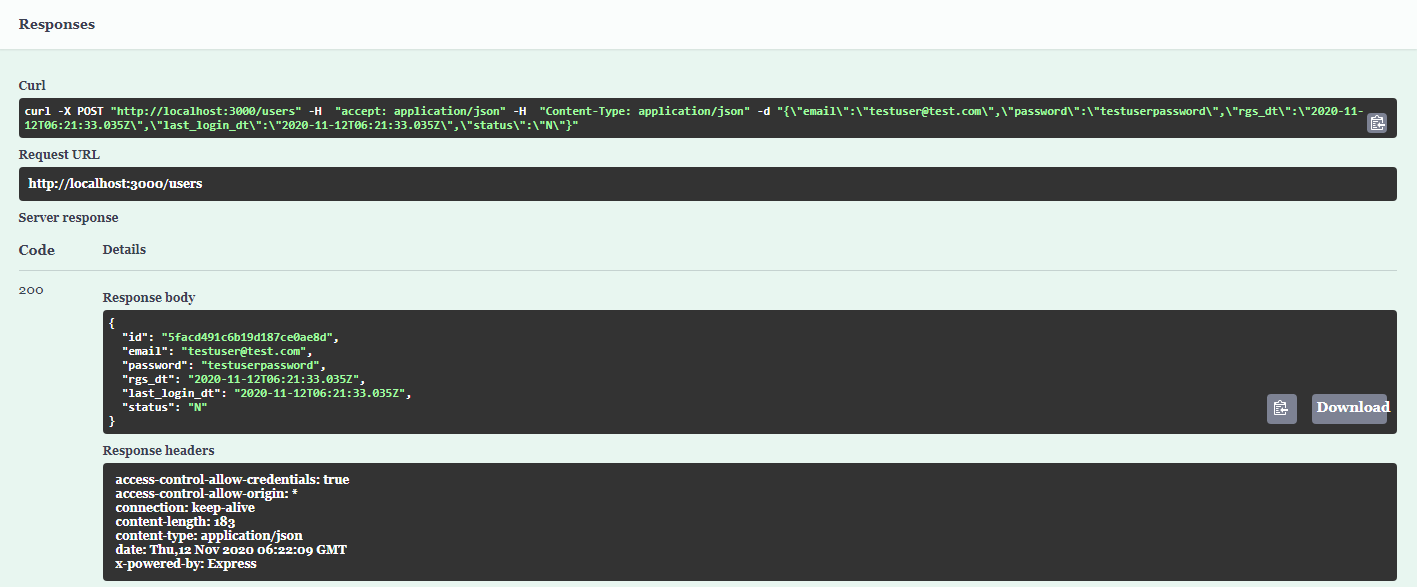
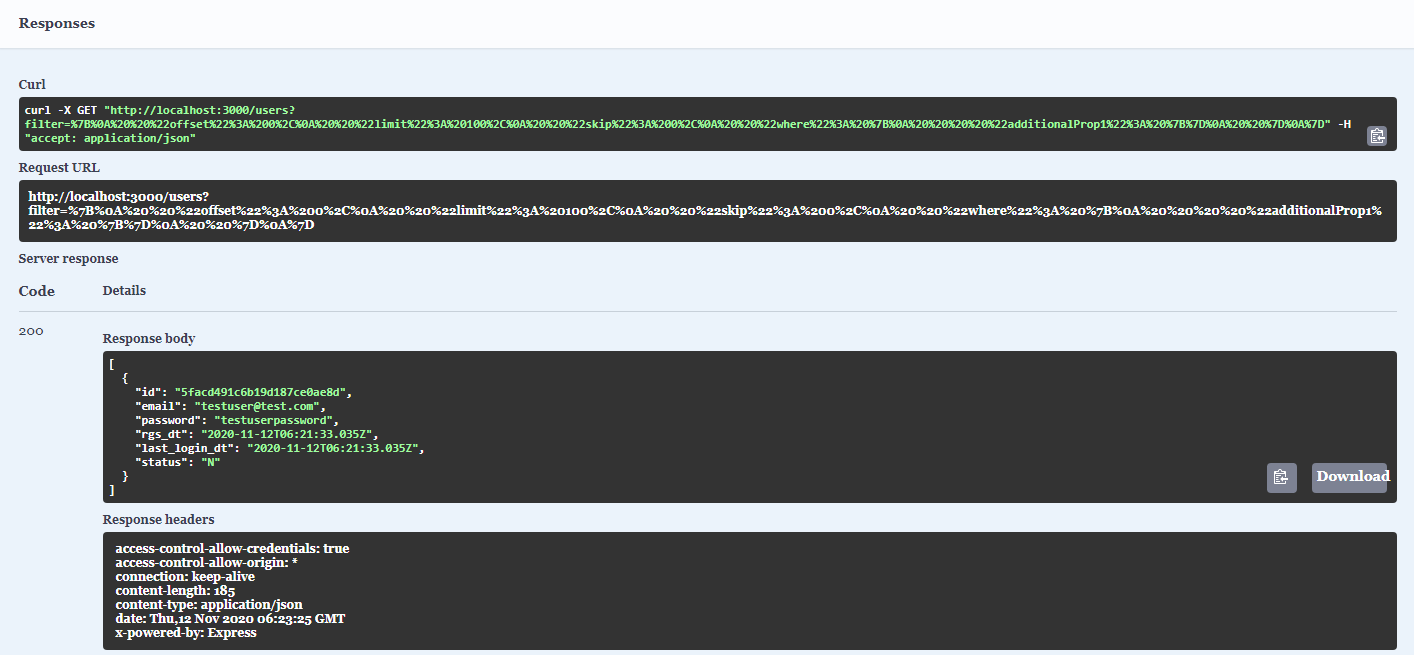
다양한 종류의 NoSQL에 대해 알아봅니다.
이 글은 다음 글을 발췌 및 번역한 글입니다: do.co/3lFbfMU
A Comparison of NoSQL Database Management Systems and Models | DigitalOcean
This article will introduce you to a few of the more commonly used NoSQL database models. It weighs some of their strengths and disadvantages, and provides a few examples of database management systems and potential use cases for each.
www.digitalocean.com
1. 소개
대부분의 사람들은 데이터베이스를 생각할 때 행(row)과 열(column)로 구성된 테이블을 포함하는 전통적인 관계형 데이터베이스 모델을 생각합니다. RDBMS는 여전히 인터넷에서 가장 많은 데이터를 처리하지만 개발자들은 관계형 모델의 한계에 대한 해결방법을 찾으려 노력함에 따라 최근 몇 년간 관계형 모델을 대체할 수 있는 데이터 모델이 좀 더 보편화되었습니다. 이러한 비 관계형 데이터 베이스 모델은 NoSQL이라 불리며 각각의 고유한 장점, 단점, 사용 사례를 확인해 보도록 하겠습니다.
이 글에서는 좀 더 일반적으로 사용되는 몇 가지 NoSQL 데이터베이스 모델을 소개합니다. 장점과 단점 중 일부를 평가하고 데이터베이스 관리 시스템의 몇 가지 예시와 각각에 대한 잠재적 사용 사례를 제공합니다.
2. 관계형 데이터베이스와 한계.
데이터베이스는 논리적으로 모델링 된 정보 또는 데이터 클러스터입니다. DBMS는 데이터베이스와 상호작용하는 컴퓨터 프로그램입니다. DBMS를 사용하면 데이터베이스에 대한 액세스를 제어하고 데이터를 쓰고 쿼리를 실행하는 등 데이터 베이스 관리와 관련된 기타 작업을 수행할 수 있습니다. DBMS는 종종 데이터베이스라고 불리지만 정확하 하자면 두 용어는 서로 동등하게 쓰일 수 없습니다. 데이터베이스는 컴퓨터에 저장된 데이터뿐 아니라 모든 데이터의 모음이 될 수 있으며 DBMS는 데이터 베이스와 상호작용할 수 있는 특정 소프트웨어일 뿐입니다.
모든 DBMS는 데이터가 저장되고 액세스 되는 방식을 구조화하는 기본 모델이 있습니다. 관계형 데이터베이스 관리 시스템(RDBMS)은 관계형 데이터 모델을 사용하는 DBMS입니다. 이 모델에서 데이터는 RDBMS의 맥락에 따라 공식적으로 관계(Relation)라고 불리는 테이블로 구성됩니다. RDBMS는 일반적으로 데이터베이스 내 보관된 데이터를 관리하고 액세스 하기 위해 SQL(Structured Query Language)을 사용합니다.
역사적으로 관계형 모델은 데이터 관리에 가장 널리 사용되는 접근 방식이며 오늘날까지 가장 널리 사용되는 DBMS도 관계형 모델을 구현합니다. 하지만 관계형 모델에는 특정 사용 사례에서 문제가 될 수 있는 몇 가지 제약사항이 존재합니다.
예를 들어 관계형 데이터베이스를 수평적으로 확장하는 것은 어려울 수도 있습니다. 수평적 확장은 부하를 분산하고 더 많은 트래픽과 더 빠른 처리를 하기 위해 기존 스택에 더 많은 머신을 추가하는 관행입니다. 이는 일반적으로 RAM 또는 CPU를 더 추가하여 기존 서버의 하드웨어를 업그레이드하는 수직적 확장과 대조되는 경우가 많습니다.
관계형 데이터 베이스를 수평적으로 확장하는 것이 어려운 이유는 관계형 모델이 일관성을 보장하도록 설계되어 있다는 사실과 관련이 있습니다. 즉 동일한 데이터 베이스를 쿼리 하는 클라이언트는 항상 최신의 데이터를 보게 해야 합니다. 여러 시스템에 걸쳐 관계형 데이터 베이스를 수평으로 확장하는 경우 클라이언트가 A노드가 아닌 B노드에 데이터를 쓸 수 있고 처음 쓴 B노드와 다른 노드들이 연결되는 시간이 존재해 변경 사항이 반영되는 업데이트 지연이 발생할 수 있어 일관성을 보장하기 어려워집니다.
RDBMS의 또 다른 제한사항은 관계형 모델이 구조화된 데이터 또는 사전 정의된 데이터 타입과 일치하거나 최소한 미리 결정된 방식으로 구성되어야 데이터를 쉽게 정렬하고 검색할 수 있도록 설계되었다는 것입니다. 하지만 1990년 이후 개인용 컴퓨터의 확산과 인터넷의 부상으로 이메일 메시지, 사진, 비디오 등과 같은 비정형 데이터가 보편화되었습니다.
이러한 제한이 더욱 크게 부각됨에 따라 개발자들은 기존의 관계형 데이터 모델의 대안을 찾기 시작하였으며 이로 인해 NoSQL 데이터베이스의 인기가 높아졌습니다.
3. NoSQL이란?
NoSQL이란 이름 자체에 대해서는 다소 모호한 정의가 있습니다. "NoSQL"은 1998년 Carlo Strozzi가 단순히 데이터 관리에 SQL을 사용하지 않았기 때문에 NoSQL 데이터베이스란 이름으로 만들어졌습니다.
이 용어는 2009년 이후 Johan Oskarsson이 Cassandra와 Voldemort 같은 "오픈소스 분산 및 비 관계형 데이터베이스"의 확산을 논의하기 위해 개발자 모임을 조직하면서 새로운 의미를 갖게 되었습니다. Oskarsson은 모임 이름을 "NoSQL"이라 명명하였으며 그 이후로 이 용어는 관계형 모델을 사용하지 않는 모든 데이터베이스에 대한 포괄적인 용어로 사용되게 되었습니다. 흥미롭게도 Strozzi의 NoSQL 데이터베이스는 실제로 관계형 모델을 사용합니다. 즉 처음의 NoSQL 데이터베이스는 현재의 NoSQL 정의에 맞지 않습니다.
"NoSQL"은 일반적으로 관계형 모델을 사용하지 않는 DBMS를 나타내므로 NoSQL 개념과 관련된 몇 가지 운영 데이터 모델이 있습니다. 다음에는 이러한 데이터 모델을 여러 개 소개합니다만 이는 전체 목록이 아닙니다.
| 운영 데이터베이스 모델 | DBMS 예시 |
| Key-value store | Redis, MemcacheDB |
| Columnar database | Cassandra, Apache HBase |
| Document store | MongoDB, Couchbase |
| Graph database | OrientDB, Neo4j |
이러한 다양한 기본 데이터 모델이 있음에도 불구하고 대부분의 NoSQL 데이터베이스는 몇 가지 특성을 공유합니다. NoSQL 데이터베이스는 일반적으로 일관성을 희생해 가용성을 최대화하도록 설계되었습니다. 여기서 일관성의 의미는 모든 읽기 작업이 데이터베이스에 기록된 가장 최근 데이터를 반환해야 한다는 생각을 의미합니다. 강력한 일관성을 위해 설계된 분산 데이터베이스에서 드는 한 노드에 기록된 모든 데이터를 다른 모든 노드에서 즉시 사용할 수 있으며 그렇지 않으면 오류가 발생합니다.
반대로 NoSQL 데이터베이스는 주로 최종 일관성을 목표로 합니다. 최종 일관성은 새로 작성된 데이터가 반드시 즉시 사용할 수 있어야 하는 것은 아니지만 결국 데이터베이스의 다른 노드에서 사용할 수 있게 됨(보통 몇 ms내에)을 의미합니다. 이렇게 하면 데이터의 가용성이 향상되는 이점이 있습니다. 작성된 최신 데이터를 즉시 볼 수 없더라고 오류가 발생하지 않고 이전 버전의 데이터를 볼 수 있습니다.
관계형 데이터베이스는 미리 정의된 스키마에 정확하게 맞는 정규화된 데이터를 처리하도록 설계되었습니다. DBMS의 맥락에서 정규화된 데이터는 중복을 제거하는 방식으로 구성된 데이터를 말합니다. 즉, 데이터베이스가 가능한 가장 적은 저장공간을 차지하도록 하는 것을 의미하며 스키마는 데이터베이스의 데이터가 구조화되는 방식에 대한 개요입니다.
NoSQL 데이터베이스는 정규화된 데이터를 저리 할 수 있고 미리 정의된 스키마 내에서 데이터를 정렬하는 것도 가능하지만 각각의 데이터 모델은 일반적으로 관계형 데이터베이스가 강요하는 견고한 구조보다 훨씬 더 큰 유연성을 허용하고 있습니다. 이 때문에 NoSQL 데이터베이스는 반정형, 비정형 데이터를 저장하는데 더 나은 선택으로 유명합니다. 하지만 NoSQL 데이터 베이스에선 사전에 정의된 스키마가 존재하지 않기 때문에 데이터베이스 관리자가 애플리케이션에 가장 적합한 방식으로 데이터를 구성하고 액세스 하는 방법을 정의해야 한다는 점을 염두해 두어야 합니다.
4. 마침.
NoSQL 데이터베이스가 무엇이며 관계형 데이터베이스와 다른 점에 대해 간략하게 파악해 봤습니다. 광범위하게 다음 글부터는 광범위하게 구현된 NoSQL 데이터베이스 모델 중 일부를 살펴보도록 하겠습니다.