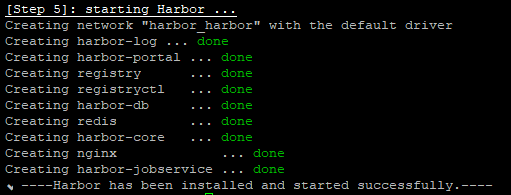
Harbor는 비교적 덜 알려진 도커 레지스트리들 중 하나입니다.공식 문서에 따르면 Harbor는 다음과 같이 설명하고 있습니다.
Harbor는 컨텐츠를 저장, 서명 및 스캔하는 오픈 소스 신뢰할 수 있는 클라우드 기본 레지스트리 프로젝트입니다. Harbor는 보안, ID 및 관리와 같은 사용자가 일반적으로 필요로 하는 기능을 추가하여 오픈 소스 Docker Distribution을 확장합니다.
빌드 및 실행 환경에 더 가까운 레지스트리를 사용하면 이미지 전송 효율성을 향상시킬 수 있습니다. Harbor는 레지스트리 간 이미지 복제를 지원하고 사용자 관리, 액세스 제어 및 활동 감사와 같은 고급 보안 기능을 제공합니다.
Harbor는 CNCF (Cloud Native Computing Foundation)에서 호스팅 합니다. 클라우드 네이티브 기술의 진화를 구체화하려는 조직인 경우 CNCF 가입을 고려하십시오. 참여자 및 Harbor의 역할에 대한 자세한 내용은 CNCF 발표를 읽으십시오.
또한 Harbor에서 제공하는 주요한 기능은 다음과 같습니다:
클라우드 네이티브 레지스트리: 컨테이너 이미지와 Helm 차트를 모두 지원하는 Harbor는 컨테이너 런타임 및 오케스트레이션 플랫폼과 같은 클라우드 네이티브 환경의 레지스트리 역할을 합니다.
역할 기반 액세스 제어: 사용자 및 리포지토리는 '프로젝트'를 통해 구성되며 사용자는 프로젝트에서 이미지 또는 Helm 차트에 대해 서로 다른 권한을 가질 수 있습니다.
정책 기반 복제: 여러 필터(리포지토리, 태그 및 레이블)가 있는 정책을 기반으로 여러 레지스트리 인스턴스 간에 이미지 및 차트를 복제(동기화) 할 수 있습니다. Harbor는 오류가 발생하면 자동으로 복제를 재 시도합니다. 로드 밸런싱, 고 가용성, 다중 데이터 센터, 하이브리드 및 다중 클라우드 시나리오에 적합합니다.
취약점 검색: Harbor는 이미지를 정기적으로 스캔하여 사용자에게 취약점을 경고합니다.
LDAP/AD 지원: Harbor는 사용자 인증 및 관리를 위해 기존 엔터프라이즈 LDAP / AD와 통합되며 LDAP 그룹을 Harbor로 가져오고 적절한 프로젝트 역할을 할당할 수 있습니다.
OIDC 지원 : Harbor는 OIDC(OpenID Connect)를 활용하여 외부 인증 서버 또는 자격 증명 공급자가 인증 한 사용자의 자격 증명을 확인합니다. Single sign-on을 사용하여 Harbor 포털에 로그인할 수 있습니다.
이미지 삭제 및 가비지 수집: 이미지를 삭제하고 공간을 재활용할 수 있습니다.
공증(Notary): 이미지 진위를 보장할 수 있습니다.
그래픽 사용자 포털: 사용자는 쉽게 저장소를 탐색하고 검색하며 프로젝트를 관리할 수 있습니다.
감사: 리포지토리에 대한 모든 작업이 추적됩니다.
RESTful API: 대부분의 관리 작업을 위한 RESTful API로 외부 시스템과 쉽게 통합할 수 있습니다. API를 탐색하고 테스트하기 위해 임베디드 Swagger UI를 사용할 수 있습니다.
쉬운 배포: 온라인 및 오프라인 설치 관리자를 모두 제공합니다. 또한 Helm Chart를 사용하여 Kubernetes에 Harbor를 배포할 수 있습니다.
만약 Harbor대신 다른 레지스트리들의 옵션을 알고 싶다면이 글을 참고해 주시기 바랍니다.
2. Harbor 설치 준비 - 요구 사양
Harbor는 리눅스에서 동작합니다. 이 글에서는 리눅스 서버 18.04.3 버전을 사용합니다.
레지스트리는 주로 Docker와 같은 컨테이너 작업을 수행하는데에 있어서 주요 구성 요소 중 하나이므로 대중들에게 매력적입니다.
레지스트리는 컨테이너 엔진의 호스트에서 다운로드되고 실행되는 이미지를 호스팅합니다. 컨테이너는 단순히 특정 이미지가 실행중인 인스턴스입니다. 이미지는 Microsoft Windows의 MSI 또는 Red Hat Enterprise Linux의 RPM과 같이 바로 사용할 수있는 패키지로 생각하면 됩니다.
여기서는 레지스트리가 어떻게 작동하는지 자세히 설명하지 않겠지만 더 자세히 알고 싶다면 이 기사를 읽어 보세요. 그 대신 제가 이 글에서 하고 싶은 것은 여전히 레이더 아래에 남아있는 몇몇의 컨테이너 레지스트리를 강조하는것 입니다.
널리 알려진 이름의 레지스트리는 Docker를 사용하는 대부분의 사람들에게 이미 익숙하지만 이미지를 호스팅 할 위치를 결정할 때 고려해야 할 가치가 있는 작은 레지스트리도 있습니다.
잘 알려지지 않은 컨테이너 레지스트리에 대한 설명은 계속 읽으시면 됩니다.
2. 잘 알려진 레지스트리들
먼저 잘 알려진 레지스트리를 식별해 잘 알려지지 않은 레지스트리와 비교할 내용을 명확히 하겠습니다.
현재 모든 계정에서 가장 인기있는 레지스트리는 Docker Hub입니다. Docker Hub는 알려진 레지스트리 세계의 중심입니다. 이건 모든 Docker 설치가 참조하도록 구성된 기본 호스팅 된 레지스트리입니다.
아마존이 Amazon EC2 Container Service (ECS)라는 호스트 된 컨테이너 서비스를 제공한다는 것을 이미 알고 있을겁니다. 그러나 아마존이 ECS를 완성하기 위해 제공하는 레지스트리는 덜 관심을받는 경향이 있습니다.
Amazon EC2 Container Registry (ECR)라고 불리는 레지스트리이며 호스트 된 Docker 컨테이너 레지스트리입니다. ECR은 ECS와 통합됩니다.
2015 년 12 월에 도입 된이 솔루션은 잘 알려진 대부분의 레지스트리보다 새로운 레지스트리 옵션으로인해 일부 사용자에게 익숙하지 않다고 설명합니다.
ECS는 ECR과 호환되는 유일한 컨테이너 레지스트리가 아닙니다. ECS는 외부 레지스트리도 지원합니다. 그러나 ECR의 주요 이점은 완전히 호스트 되고 관리되는 레지스트리이므로 배포 및 관리가 간단하다는점 입니다. 또한 ECR은 다른 ECS 인프라만큼 확장 가능하므로 확장성이 매우 뛰어납니다.
최고의 사용 사례는 다음과 같습니다: AWS 서비스를 많이 사용하거나 사용할 계획을 갖고 있으며 개인 이미지를 호스팅 할 장소를 찾고 있다면 ECR을 사용하는 것이 좋습니다. 대규모 레지스트리 배포가 있거나 시간이 지남에 따라 레지스트리가 크게 확장 될 것으로 예상되는 경우에도 좋은 선택입니다. 이 경우 사실상 제한없이 ECR을 확장할 수 있습니다.
3.2. FlawCheck Private Registry
FlawCheck Private Registry (보안 업체 Tenable이 FlawCheck의 나머지 비즈니스와 함께 최근에 인수 함)는 보안을 중점으로 한 레지스트리 옵션입니다.
이 레지스트리는 컨테이너 이미지에 대한 통합 취약성 검색 및 말웨어 탐지 기능을 제공합니다. 컨테이너 이미지에 악성 코드가 없어지게 하거나 레지스트리에 악성 이미지가 삽입되는 것을 막는 만능 도구는은 아니지만 FlawCheck의 스캔 기능은 위험을 줄이는데 도움이 될 수 있습니다.
최상의 사용 사례는 다음과 같습니다: 보안에 민감한 회사의 경우이 방법이 정말 좋습니다. 규제가 심한 산업에서는 이 레지스트리를 많이 채택 할 것으로 예상됩니다.
3.3. GitLab Container Registry
호스트 또는 온-프레미스 레지스트리로 실행할 수있는 GitLab Container Registry는 컨테이너 이미지 호스팅을위한 GitLab의 솔루션입니다. GitLab에 내장되어 있으며 나머지 GitLab의 도구들과 완벽하게 호환되므로 GitLab 딜리버르 파이프 라인에 직접 통합 될수도 있습니다.
팀이 가능한 한 적은 움직이는 부품으로 완벽한 DevOps 워크 플로우를 탐색하고 있다면 이를 채택하는것이 좋습니다.
최상의 사용 사례는 다음과 같습니다: 일부 개발자는 Docker 이미지를 소스 코드와 동일한 플랫폼에 저장하는 것이 편리하다는 것을 알게 될 것입니다. 소스 코드에 GitLab을 사용한다면 GitLab Container Registry가 유용 합니다. 그러나 GitLab Container Registry는 대부분의 다른 레지스트리에서 사용할 수없는 킬러 기능을 제공하지 않습니다.
3.4. SUSE의 Portus
Portus는 기술적으로 레지스트리는 아니지만 Docker Registry의 온-프레미스 배포를 위해 기본 UI를 대체하는 프런트 엔드를 제공합니다.
Portus는 추가 액세스 제어 옵션을 제공하여 Docker Registry에 가치를 더하도록 설계되었습니다. 여기에는 팀 또는 레지스트리 사용자를 서로 다른 액세스 수준을 설정하여 구성하는 기능이 포함됩니다.(여러 가지면에서이 기능은 Unix 계열 시스템의 사용자 그룹과 유사합니다.)
또한 Portus는 레지스트리 네임스페이스를 제공해 팀의 사용자 뿐 아니라 개인 사용자에게 다른 저장소에 대해 세부적으로 수행할 수 있는 수정 유형 구성을 만드는것을 가능하게 합니다.
그리고 Portus는 레지스트리 설정 및 액세스 제어를 구성 할 수있는 사용자 친화적 인 웹 인터페이스를 제공합니다. CLI 구성 도구 인 portusctl도 사용 가능합니다.
최상의 사용 사례는 다음과 같습니다: Docker Registry를 좋아하지만 추가 보안 제어가 필요하거나 세분화 된 액세스 제어를 사용해야하는 이유가있는 경우 Portus는 강력한 솔루션입니다.
3.5. Sonatype Nexus
호스트 및 온-프레미스 배포를 지원하는 Sonatype Nexus는 범용 리포지토리입니다. 이는 Docker 이미지 호스팅보다 훨씬 많은 것을 지원하지만 Docker 레지스트리로도 사용될 수 있습니다.
Docker보다 훨씬 오래 되었으며 이전에 컨테이너 레지스트리를 사용하지 않았더라도 노련한 관리자에게는 익숙 할 것입니다.
핵심 Nexus 플랫폼은 오픈 소스이지만 상용 옵션 또한 제공됩니다.
최상의 사용 사례는 다음과 같습니다: 많은 회사에서 Nexus를 Maven의 저장소로 몇 년 동안 배포해 왔습니다. 플랫폼의 최신 릴리스로 업그레이드하기 만하면 조직에서 Docker 이미지 호스팅을 추가하여 새로운 제품에 대한 개발 또는 운영 직원을 교육하지 않고도 자체 Docker 레지스트리를 만들 수 있습니다. 또한 Docker 이미지와 함께 다른 유형의 제작물를 호스팅 할 수 있습니다.
3.6. VMware Harbor Registry
Docker 생태계에서 VMware를 주요 플레이어로 생각하지는 않지만 이 회사는 확실히 새로운 시도를 하고 있습니다. Harbor Registry는 Docker 이미지 호스팅에 대한 VMware의 결과입니다.
이 레지스트리는 Docker Distribution을 기반으로 구축되었지만 보안 및 ID 관리 기능을 추가하였습니다. 또한 단일 호스트에서 여러 레지스트리를 지원합니다.
최상의 사용 사례는 다음과 같습니다: Harbour는 보안 및 사용자 관리에 중점을두고 있기 때문에 이 옵션은 기업이 추구하는 중요한 레지스트리 기능을 제공하며 이 기능은 다른 모든 레지스트리에서 사용할 수 있는것은 아닙니다. 이는 기업에서 좋은 선택입니다.
Harbor는 Docker 컨테이너로 실행되기 때문에 Docker 환경이있는 모든 서버에 쉽게 설치할 수 있으며 개발자에게 오프라인 설치 프로그램을 제공하기 때문에 보안 고려 사항 또는 기타 요인이있는 상황(공용 인터넷에 연결할 수 없는 경우을 의미합니다.)에서 유용 할 수 있습니다.
4. Conclusion
서로 다른 레지스트리 오퍼링 사이의 주요 변수에는 지원하는 배포 환경 유형 (호스트, 온 프레미스 또는 둘 다)이 포함됩니다. 액세스 제어 옵션을 얼마나 미세하게 조정했는지; 컨테이너 레지스트리에 대한 추가 보안 수준.
물론 필요에 맞는 레지스트리를 선택하는 것은 이러한 기능이 우선 순위에 어떻게 부합하는지에 달려 있습니다. 그러나 선택의 폭이 넓기 때문에 특정 조직의 요구에 완벽한 균형을 제공하는 레지스트리를 찾는 것은 어렵지 않을겁니다.
init에서 필요한 변수를 미리 지정해 둡니다. '만약 로컬에 기본값으로 설치했다면 url에 localhost, port에 5672를 사용하면 됩니다. vhost와 queue는 앞에서 생성 한 대로 입력했습니다. cred는 vhost 액세스 권한이 부여된 계정을 입력하면 됩니다.
코드 내용은 단순합니다. BlockingConnection을 이용해 커넥션을 생성합니다. chan에 생성된 연결에서 채널을 가져 온 후 basic_publish를 이용해 메시지를 발행합니다.
exchange에 빈값을 넣어 default exchange를 사용하도록 하였으며 routing_key에 타겟 큐 이름을 넣었습니다. body엔 메시지 내용을 입력하면 됩니다.
이렇게 한번 실행하면 t_msg_q에 Hello RabbitMQ라는 메시지가 한번 생성되고 종료하는 publisher를 만들었습니다.
실제로 MQ 관리자 페이지에서 queue를 눌러보면 메시지가 들어온 것을 확인할 수 있습니다.
on_message는 메시지를 수신했을 때 실행 될 콜백 함수입니다. 이 예제에서는 단순히 받은 메시지를 출력하는 역할을 하고있습니다.
채널까지 생성한 후 basic_consume를 통해 메시지를 소비하는 방법을 정의합니다. queue엔 앞서 생성한 큐의 이름을 넣어주면 되고 on_message_callback에는 앞에서 정의한 콜백 함수를 넣어줍니다. auto_ack는 메시지를 소비했을 때 자동으로 ack을 날릴지 여부입니다. ack을 mq에 전송하면 소비된 메시지는 제거됩니다.
그 후 start_consuming()을 실행하면 지속적으로 큐에 있는 메시지를 소비하는 상태가 됩니다. 중단하고 싶으면 Ctrl + C를 눌러 중단하면 됩니다.
이제 파이썬을 실행시키면 다음과 같이 메시지가 출력됩니다.
아까 발행한 메시지를 정상적으로 소비하였습니다. 관리자 페이지로 이동해 보면 auto_ack 옵션에 따라 전송된 ack에 의해 메시지가 삭제된 것을 확인할 수 있습니다.
우선 url이 세 개로 늘었습니다. auto_token을 받아오는 메인 페이지, 로그인을 요청하는 페이지, 이슈를 조회하는 페이지가 있습니다. 로그인 시 사용하는 객체는 __login_data에 저장해 두었으며 __issues는 조회한 이슈를 정리하여 담아두기 위한 객체입니다.
실제 작업의 워크 플로우를 봅시다.
먼저 세션을 생성하고 세션 내에서 auth_token을 구해옵니다. 구해온 토큰은 __login_data에 저장해 두었습니다.
이제 로그인시 필요한 정보가 모두 모였으니 로그인을 시도합니다. status_code를 확인해 정상적으로 로그인이 되었다면 조회를 시작합니다.
조회 결과를 search_req에 담아둔 뒤 BeautifulSoup를 이용해 객체로 변환합니다.
모든 HTML이 아닌 위에 보이는 테이블의 헤더와 row정보만 필요하므로 셀렉터를 사용해서 값을 추출해주었습니다.
추출한 값을 루프 문을 통해 각각의 이슈를 객체로 만든 뒤 리스트에 담아두었습니다. 모든 작업이 끝나면 시간과 함께 JSON으로 만들기 위해 __issues에 저장한 후 출력까지 해보았습니다.
값이 위와 같이 잘 나오시나요? 이로써 가장 간단하고 기초적인 크롤러를 만들어보았습니다. 다음에는 이 크롤러를 좀 더 발전시켜보도록 하겠습니다.